2 Architecture III - TP N°2 - Ordonnancement des processus - Gestion mémoire
Table des matières
2.1 Objectif
L'objectif de ce TP est d'étudier un certain nombre d'algorithmes d'ordonnancement afin de comprendre l'ordonnancement dans le système UNIX et observer la gestion mémoire.
Selon les politiques d'ordonnancement, des manipulations sont proposées à l'aide de logiciels de simulation.
2.2 Ordonnancement des processus
Rappels
- Scheduler (ordonnanceur) : Assure la distribution de l'UC aux différents processus.
- Sans réquisition : le processus se termine complètement avant de rendre la main au scheduler (non préemption)
- Avec réquisition : le scheduler prend la main sur le processus. Cela entraîne des problèmes dans le partage de ressources entre processus (préemption).
- Dispatcheur : Assure lors du changement de processus, la commutation de contexte, la commutation en mode utilisateur, le branchement au bon emplacement dans le programme utilisateur. Il doit être le plus rapide possible (latence de dispatching).
Différents algorithmes d'ordonnancement
L'analyse de certains algorithmes est illustrée avec le programme Simor. Simor est un simulateur graphique d'ordonnancement qu'il faut lancer à partir de de la commande
java -jar /home/partage/S51/Simor.jar
Présentation du simulateur Simor
Lancer le simulateur avec la commande précédente et découvrez l'interface utilisateur.
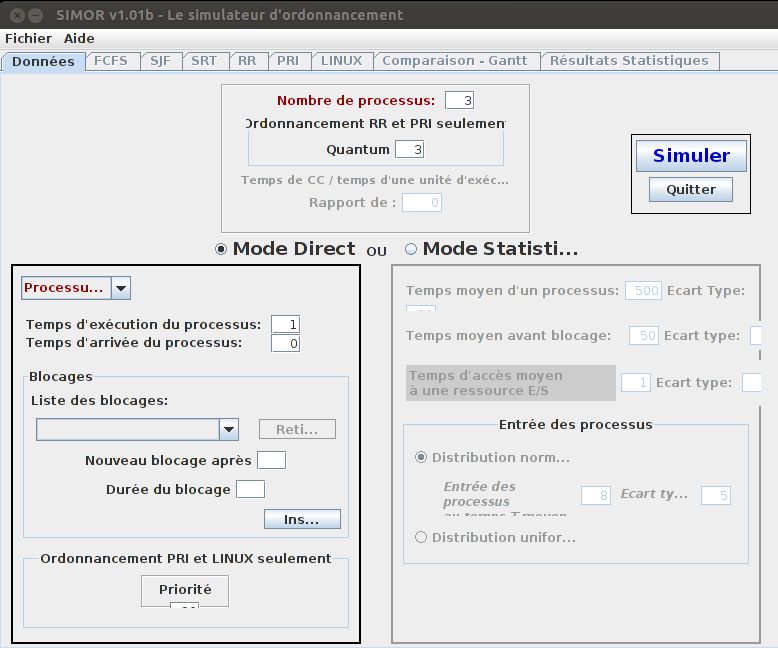
La zone centrale de la partie haute de Simor permet de définir le nombre de processus dans la simulation ainsi que le quantum pour le système Tourniquet (Round Robin).
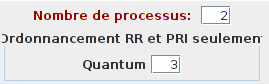
La zone basse dans la partie gauche permet de définir les paramètres des différents processus créés : leur temps d'exécution nécessaire et leur date d'arrivée.
La zone droite du simulateur présente le bouton principal permettant de lancer la simulation pour toutes les politiques d'ordonnancement définies dans Simor.
L'écran de Simor présente une barre d'onglets et 3 zones.
Les résultats de la simulation s'affichent dans chacun des onglets de la barre d'onglets dans la partie supérieure du simulateur.
Divers graphiques de simulation et différentes valeurs sont proposées pour chaque politique.

Algorithme FCFS (FIFO) : First Come-First Served
- Créez deux processus avec comme temps d'exécution de 15 s et un retard au départ de 2 s.
- Lancez la simulation et visualisez le résultat dans l'onglet FCFS. Que se passe-t-il ? Dans quel ordre sont élus les processus ?
- Recommencez l'opération en créant un troisième processus avec comme durée 30 s et un retard au départ de 0s.
- Que se passe-t-il ? Que provoque le processus 3 d'une durée plus longue ?
- Essayez cet algorithme avec des valeurs différentes de durée et de retard au départ.
- Quels sont les avantages et inconvénients de cet algorithme pour l'exécution des processus ? Que peut-on dire du temps moyen d'attente (tma) d'un processus pour accéder au processeur ?
- Calculer le « tma » pour 3 processus P1, P2, P3 d'une durée respective de 50 s, 25 s et 8 s et aucun retard au départ.
Algorithme SJF : Shortest-Job-First (PCTE)
SJF = le prochain job dont le cycle d'UC est le plus court (mode non préemptif)
- Créez 3 processus avec les paramètres suivants:
- P1 (d= 5 s, r= 0 s),
- P2 (d= 7 s, r= 0 s),
- P3 (d= 3 s, r= 0 s).
- Lancez la simulation et analysez les résultats de l'onglet SJF.
- Que constatez-vous ? Comment fonctionne cet algorithme ?
- Créez un quatrième processus avec les paramètres suivants: P4 (d=2 s, r=4 s). Observez son fonctionnement.
- Expérimentez encore avec un cinquième processus P5 (d=2 s, r=3 s).
- Quels sont les avantages et inconvénients de cet algorithme pour l'exécution des processus ? Que peut-on dire du temps moyen d'attente d'un processus pour accéder au processeur ?
- Calculez le « tma » pour 3 processus P1, P2, P3 d'une durée respective de 50 s, 25 s et 8 s et aucun retard au départ.
Algorithme RR : scheduling du tourniquet, Round-Robin
Conçu spécialement pour les systèmes en temps partagé. Similaire au FCFS mais avec préemption après une tranche de temps (quantum) d’exécution (généralement entre 10 & 100 ms).
- Créez 4 processus avec les paramètres suivants:
- P1 (d= 50 s, r= 0 s),
- P2 (d= 70 s, r= 0 s),
- P3 (d= 30 s, r= 0 s),
- P4 (d= 80 s, r= 0 s),
- un quantum de 10 s.
- Lancez la simulation et observez l'exécution des processus pour la politique RR. Que se passe-t-il ?
- Calculez le temps d'attente maximal pour ces 4 processus.
- Recommencez le test en réglant le quantum à 1 s. Que constatez-vous ?
- Recommencez le test en réglant le quantum à 90 s. Que constatez-vous ?
- A quel algorithme ressemble maintenant l'allocation du processeur ?
- Calculez le « tma » pour 3 processus P1, P2, P3 d'une durée respective de 500 s, 250 s et 80 s avec un quantum de 1 s et aucun retard au départ.
- A quel algorithme ressemble maintenant l'allocation du processeur ?
- Quel est l'inconvénient du tourniquet et dans quelles conditions apparaît-il?
Algorithme de scheduling du noyau UNIX
Le scheduling de l'UC est conçu pour qu'en bénéficient les processus interactifs. Un algorithme avec des priorités donne aux processus de courtes tranches de temps d'UC. Cet algorithme se réduit à un scheduling de type tourniquet.
Une priorité de scheduling est associée à chaque processus; un nombre plus grand indique une priorité plus petite. Les processus qui effectuent des entrées sorties ou d'autres taches importantes possèdent des priorités importantes et on ne peut les préempter (exécution en mode noyau). Les processus utilisateurs possèdent des priorités faibles (donc inférieures au processus noyau). Il est possible de régler les priorités des processus utilisateurs avec la commande nice().
Plus un processus accumule du temps processeur, plus basse devient sa priorité (plus grande valeur) et vice-versa. Il existe donc un feedback négatif dans le scheduling de l'UC, et il est difficile pour un seul processus de prendre tout le temps processeur. Le vieillissement des processus est donc utilisé pour éviter la famine.
NB : À noter que le scheduling de LINUX prévoit dans son extension POSIX 1003.4, la notion de processus temps réel et dispose de 2 politiques supplémentaires SCHED_FIFO et SCHED_RR avec dans ce cas des priorités fixes. Les processus s’exécutant suivant ces politiques s’exécutent de façon prioritaire par rapport aux processus classiques à priorité dynamique. Ils sont cependant préemptables par le système et ne peuvent bloquer le processeur. Ces modes ont été rajoutés pour apporter au système un certain contrôle de la réactivité face à des événements extérieurs à la machine, le but étant d’essayer d’intégrer du déterminisme dans le traitement des processus.
2.3 Test de la commande nice
La commande nice permet de modifier la priorité d'un processus. L'utilisateur peut seulement ralentir la priorité d'un processus en ajoutant une valeur (de 1 à 19) à la valeur actuelle de la priorité du processus (par défaut le facteur nice est à 0). L'administrateur peut augmenter ou diminuer la priorité d'un processus (de -20 à 19).
La syntaxe est : nice -valeur 'programme à exécuter'.
Cette commande est aussi accessible à partir de l'API C. Afin de visualiser l'effet du changement de priorités des processus nous allons exécuter deux processus identiques qui effectuent un calcul long et d’observer la variation du temps d’exécution lorsqu’on fait varier la priorité du processus avec des appels C à la fonction nice().
2.4 Attention
Pour cette exercice sur la commande nice, afin de mieux voir l'effet escompté tous les processus s'exécuteront sur le même processeur. Or maintenant de plus en plus de processeur sont multi-coeurs, ce qui est vu par le système comme une architecture multiprocesseurs. Pour connaître le nombre de processeur de votre machine, tapez la commande suivante dans un terminal shell:
grep -c processor /proc/cpuinfo
La réponse sur le terminal indiquera le nombre de processeur.
Si ce nombre est 1, il n'y a qu'un seul processeur. Sinon, le programme utilisé force son exécution (les processus DemoNice) à s'exécuter sur le même processeur. Pour cela, il modifie ce que l'on appelle le cpu affinity.
2.5 Questions
Lancez deux instances du programme DemoNice en tapant /home/partage/S51/demoNice et observez la variation du temps d’exécution en jouant sur le facteur nice.
Que se passe-t-il si un programme (A) a comme facteur 19, par rapport à un programme (B) qui a un facteur 0 ?
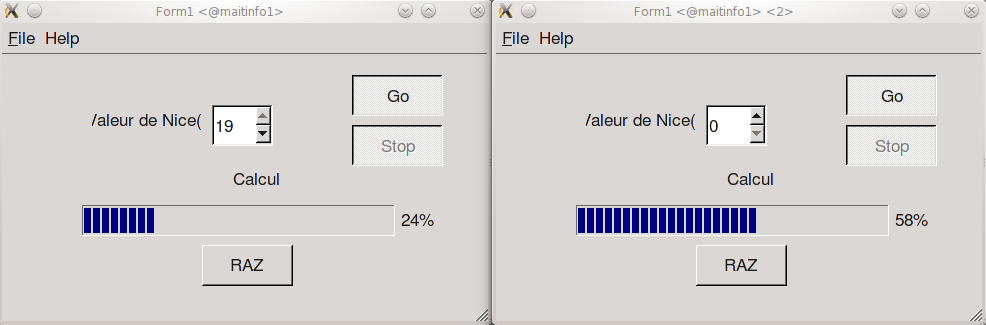
Que se passe-t-il si le programme (B) est bloqué ?
Fermez les deux programmes précédemment lancés et exécutez 2 nouvelles instances avec comme facteur nice 0 et 5. Quel se passe-t-il ? Pourquoi est ce différent du cas précédent ?
Fermez les deux programmes précédemment lancés et exécutez 3 nouvelles instances avec comme facteur nice 0, 10 et 19. Quel est le résultat ?
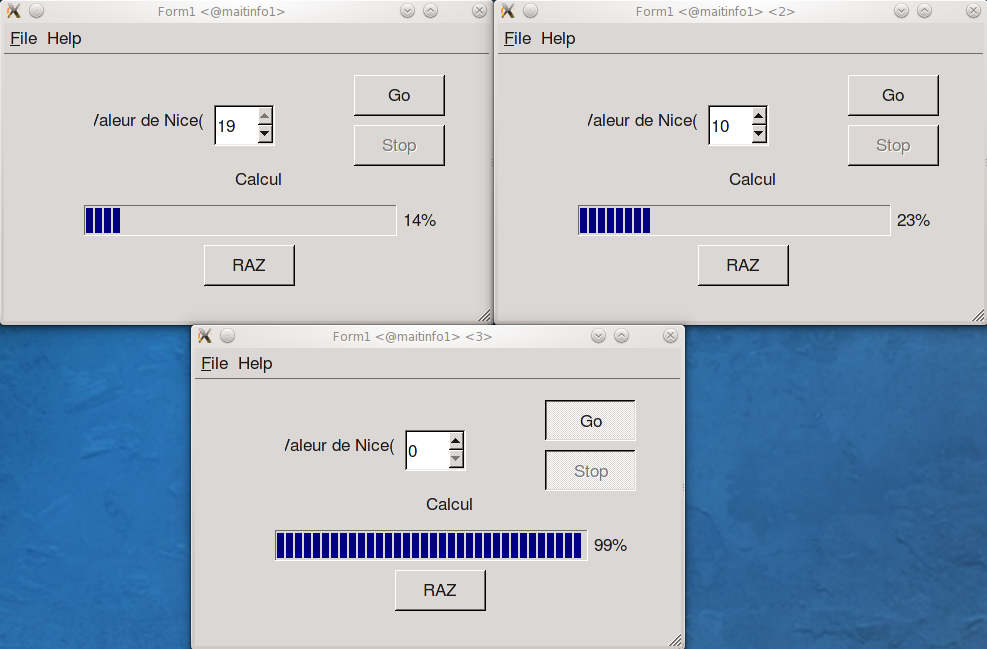
Recommencez la dernière question en mesurant avec la commande time les temps d'exécution de chaque processus. Vous stopperez les processus dés que le premier (nice =0) aura fini son calcul en cliquant sur le X de la fenêtre.
NB: les valeurs seront partiellement différentes pour le temps d'exécution. Ceci est dû au lancement et l'arrêt séquentiel des processus, mais l'erreur introduite est négligeable pour la mesure voulue. Utilisez trois terminaux pour ce test. Que constate-t-on ?
Lancez de nouveau deux instances de demoNice en tapant /home/partage/S51/demoNice dans un terminal. Dans un autre terminal lancez la commande top. Filtrez l’affichage de top pour afficher ces deux processus. Changez les valeurs de nice dans les deux fenêtres (par ex 5 et 12).
Vérifiez la prise en compte au niveau système de vos modifications dans l’interface de top. Ré-affichez la liste des différents processus. Quelle est la valeur nice de la plupart des processus actifs ?
2.6 Pagination
Politique de remplacement
Le programme Simdef.jar permet de simuler les algorithmes d'allocation et de remplacement de page. Expérimentez ce programme (à démarrer avec java -jar) en définissant une séquence de 10 demandes de page avec les valeurs suivantes: 1, 2, 3, 4, 1, 2, 4, 3, 1, 5.
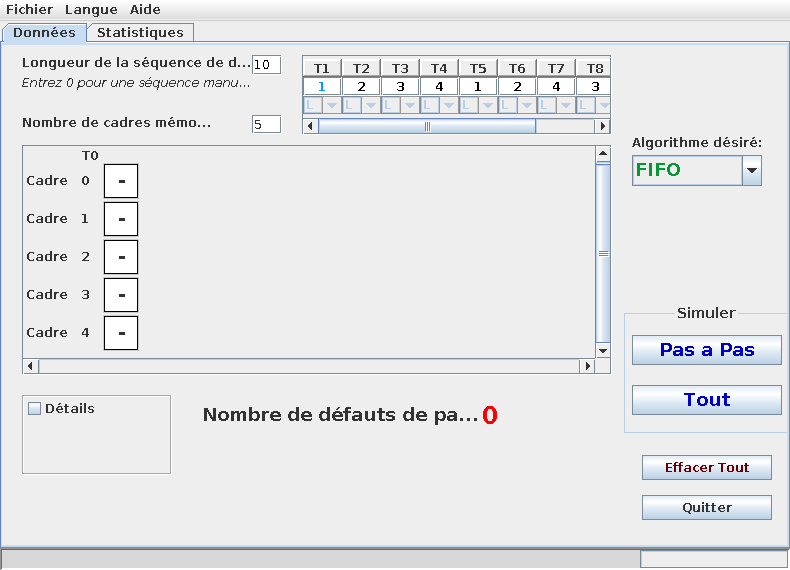
- Fixez le nombre cadres mémoire à 5. Quel est le nombre de défauts de page pour chacune des politiques de remplacement ?
- Fixez maintenant le nombre de cadres à 4. Quel est le nombre de défauts de page pour chacune des politiques de remplacement ?
- Fixez maintenant le nombre de cadres à 3. Quel est le nombre de défauts de page pour chacune des politiques de remplacement ?
- Fixez maintenant le nombre de cadres à 2. Quel est le nombre de défauts de page pour chacune des politiques de remplacement ?
- D'après vos observations et ce que vous savez des algorithmes de remplacement simulés, qu'en concluez-vous sur le choix de la politique ?
Traduction d'adresses
Le programme Simav.jar permet de simuler le processus de traduction d'adresses virtuelles dans un système paginé. Exécutez ce programme (à démarrer avec java -jar également). Utilisation:
- Commencez par sélectionner une table des pages à 1 niveau (menu Niveaux).
- Entrez une adresse dans la zone prévue. Sa décomposition en numéro de page - déplacement binaire apparaît. La position de l'adresse virtuelle indiquée est également représentée sur la partie gauche de la fenêtre.
- Le bouton Simuler permet de lancer le processus de traduction de l'adresse vers la table des pages. En cas de défaut de page (la page n'est plus en mémoire), vous devez indiquez un emplacement en mémoire physique dans lequel sera placée la page.
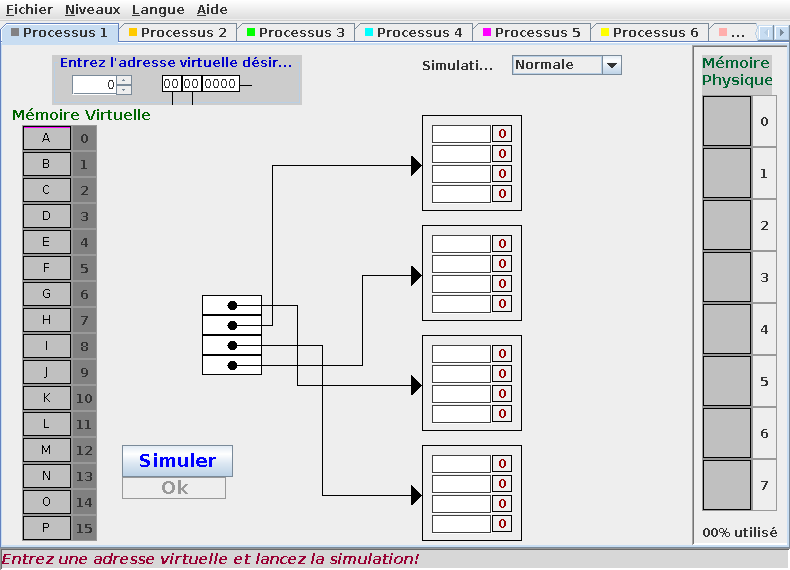
Effectuez des traductions successives afin d'expérimenter et bien comprendre le processus de traduction d'adresses paginées avec table des pages. Expérimentez ensuite la traduction avec une table des pages à 2 niveaux.
Allocation/Libération mémoire
Analysez les valeurs les fichiers /proc/meminfo et /proc/vmstat afin de repérer les données importantes permettant par exemple de connaître les demandes de pages, le nombre de défaut de page, déduire la taille d'une page etc. .. qui corroborent les données affichées par le programme précédent.
Le but des exercices suivant est de suivre et analyser l'occupation mémoire d'un processus selon son code et la mémoire dont il a besoin.
Pour suivre cette occupation, vous utiliserez la commande atop et suivrez les changements apparu dans le programme et les fichiers précédents avant et après exécution. Dans top, htop et atop, l'occupation mémoire est exprimée au minimum en kio.
Les options intéressantes de atop sont:
- m: affichage des informations mémoires
- i: changement du délai de rafraichissment des informations
- c: commandes exécutées (avec arguments)
- P: filtrage du nom des processus
- z: pause du rafraichissment de l'affichage
Lancez le programme /home/partage/S51/slp qui effectue l'instruction sleep(10). Quelle est son occupation mémoire, la taille des segments (text et data)?
Vous allez maintenant essayer de déterminer la taille d'une page mémoire en faisant varier l'occupation mémoire. Pour cela, vous allez utiliser le programme /home/partage/S51/alloc qui permet d'allouer un nombre d'octets passés en paramètre de ce programme et attend 10 s avant de se terminer.
Sachant que la taille T d'une page est une puissance de 2 (1, 2, 4, 8, etc), pour plusieurs valeurs de T, exécutez en parallèle (en mode détaché) 5 instances du programme alloc avec les valeurs suivantes et notez leur occupation mémoire respective:
- un octet,
- un entier,
- T - 100 octets, (si T est supérieur à 100)
- T + 100 octets, (si T est supérieur à 100)
- 2 * T
Déduisez-en la taille T d'une page dans le système.
2.7 Système de fichiers
Rappels sur quelques commandes
Quelles sont les commandes pour:
- renommer un fichier,
- changer de répertoire,
- créer un répertoire,
- créer un fichier vide,
- effacer un fichier,
- effacer un répertoire,
- effacer un répertoire et son contenu,
- compter le nombre de ligne du fichier /etc/passwd,
- compter le nombre de fichiers (et répertoires) dans un répertoire (attention à l'utilisation du *),
- compter le nombre de fichiers mais sans inclure les répertoires.
Les commandes df (disk free) et du (disk use)
- Combien il y a-t-il de systèmes de fichiers montés sur le système ? A quoi correspondent ils ?
- A quel système appartient votre répertoire de connexion ? Combien reste-t-il d'espace disque libre ?
- Quelle option de du et df permet d'afficher les valeurs en multiples d'octets (Ko, Go …) ?
- Quel espace occupe votre répertoire de connexion ?
- A l'aide des commandes du et sort (voir les pages man), affichez la liste des fichiers et répertoires situés dans /etc, classée suivant l'espace disque qu'ils occupent.
Les i-nodes
Sous Unix/Linux, pour la gestion du système de fichiers, chaque fichier est identifié par un numéro unique: l'i-node. A cet identifiant est associé plusieurs information concernant le fichier qui permettent au système d'exploitation de bien gérer les actions liées au système de fichiers. Parmi ces informations on retrouve le type, la taille et le contenu du fichier.
- Avec quelles options les commandes ls et stat permettent de voir ces informations (taille, i-node, droits etc) ?
- Comment afficher à l'aide de la commande ls la liste des fichiers triée du plus ancien au plus récent, en affichant cette date, les droits, la taille etc ?
Sous Unix/Linux il existe la possibilité de créer des liens entre fichiers afin de permettre par exemple de créer plusieurs noms faisant référence au même i-node, et donc au même fichier. Pour cela il faut utiliser la commande ln. Il existe deux types de lien: les liens physiques (hard link) et les liens symboliques (soft link).
2.8 Liens physiques
- Créez deux fichiers: le fichier one contenant la valeur 1 et le fichier two contenant la valeur 2.
- Créez ensuite à l'aide de la commande ln le fichier un et le fichier deux en tant que lien physique vers respectivement one et two.
- Comment apparaissent ces deux fichiers avec la commande "ls -l" ?
- Modifiez le fichier one pour y mettre la valeur 3. Que contiennent les fichiers one, two, un et deux ? Que remarquez-vous ?
- Quels sont les i-nodes de ces 4 fichiers ?
- Que fait donc la commande ln en création de lien physique ?
- Comparez l'i-node du dossier courant et l'i-node du dossier ”.” situé dans le dossier courant ? et l'i-node de ”..”, à quel répertoire correspond-t-il ? Expliquez.
2.9 Liens symboliques
Les fichiers de lien symbolique contiennent une référence à un autre fichier et leur contenu “simplement” par un chemin (absolu ou relatif) vers l'autre fichier. Comme pour les liens physiques, toutes les commandes effectuées sur un fichier lien sont en fait effectuées sur le fichier référencé. Mais contrairement aux liens physiques, il y a bien deux fichiers différents qui sont créés car ils ont deux i-nodes différents. On dit simplement que le fichier lien pointe vers un autre fichier.
Pour créer un lien symbolique il suffit d’ajouter l’option -s à la commande ln. En effet, par défaut la commande ln crée un lien physique. La commande "ls -l" permet d’identifier les liens non seulement par leur type mais aussi par le fichier référencé. De plus il est possible de créer des liens vers des répertoires car tout répertoire est en fait un fichier.
- Créez un répertoire FR et un répertoire EN.
- Notez les i-nodes des fichiers un, deux, one et two
- Placez dans FR les fichiers un et deux précédents et dans le répertoire EN les fichiers one et two précédents.
- Leurs i-nodes ont-ils changé ?
- Créez dans le répertoire FR le fichier trois contenant la valeur 3.
- Créez dans le répertoire EN le fichier three en tant que lien symbolique vers le fichier trois du répertoire FR.
- Quels sont les i-nodes de ces deux fichiers ? Qu'affiche la commande ls -l dans le répertoire EN ?
- Créez au même niveau que les répertoires EN et FR le nouveau répertoire US comme étant un lien symbolique de EN. Quel est l'i-node de US ? Le répertoire US contient-il des fichiers et si oui à quoi correspondent leur i-nodes ?
- Modifiez la valeur du contenu de US/three à la valeur 3.0 . Quel est le contenu des fichiers FR/trois et EN/three ?
- Ouvrez dans un éditeur le fichier US/three et laissez le ouvert (par exemple vim, emacs). En parallèle, après avoir fait un ls, supprimez le fichier FR/trois et faire de nouveau ls. Modifiez dans l'éditeur la valeur par 3 et sauvez le fichier (en gardant l'éditeur ouvert). Refaire ls. Que remarquez-vous ?
- Comment peut-on connaître le nombre de noms/liens que possède un fichier ?